High-throughput Biology - From Sequence to Networks 2019 - Lab 17
This work is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License. This means that you are able to copy, share and modify the work, as long as the result is distributed under the same license.
iRegulon Lab Practical
By Veronique Voisin
Goal
Import a Cytoscape network and apply iRegulon on all the selected nodes. Explore and understand the main output features of iRegulon such as the Transcription target view. Learn how to display predicted targets of a specific transcription factor by creating its metatargetome.
This practical consists of 2 exercises. You can choose to do these exercises using the questions as your only guide - or see the the step-by-step checklist to finding the answers. Some notes about iRegulon and information about the output values are written at the end of the document.
Before starting the exercises, download the files:
Note: in case the iRegulon server is not working, it is possible to work with precomputed results. Please look at the instructions at the bottom of this page.
Exercise 1. Detect regulons from co-expressed genes
In this exercise, we will continue to use the genes from the prostate cancer list from the GeneMANIA assignment. iRegulon requires a network from the start, and we will use the GeneMANIA network that we previously saved for this purpose. Using iRegulon, we will look for transcription factors (TFs) that may regulate a set of genes in this network.
To start this exercise, download to your computer the prostate_cancer_genemania_network.txt file.
Skills learned in this exercise:
Create a network by importing a text file, run iRegulon to detect regulons, explore the iRegulon results, create a regulon subnetwork, save the results.
Steps
1) Launch Cytoscape. Close the “Welcome to Cytoscape” window, if it’s enabled.
2) Create a network using the ‘prostate_cancer_genemania_network.txt’ file.
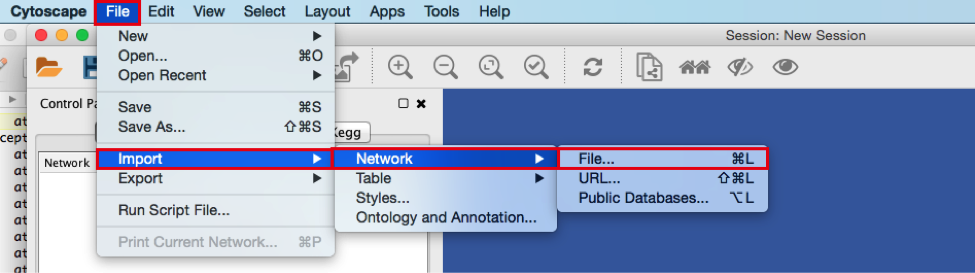
● In the menu bar select ‘File > Import > Network from File…. A file open dialog pops up.
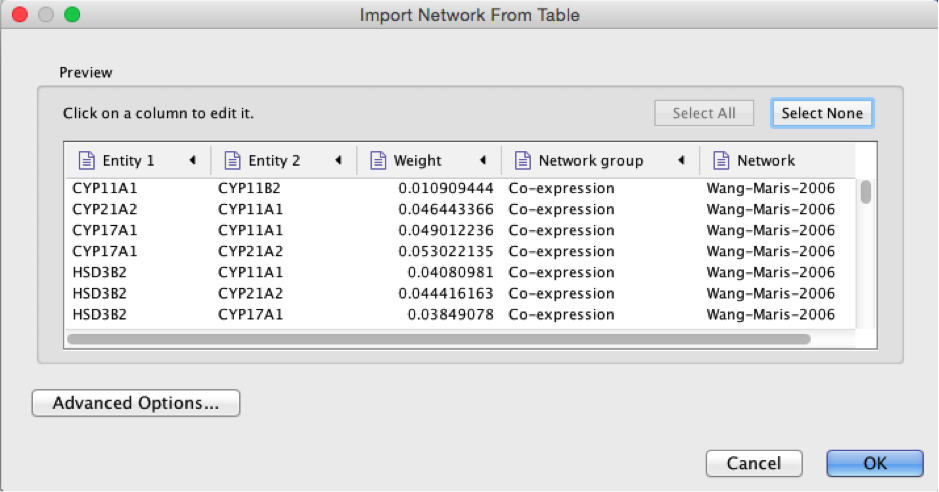
● Browse and locate the prostate_cancer_genemania_network.txt’ file. Click the ‘Open’ button. An “Import Network From Table” dialog pops up.
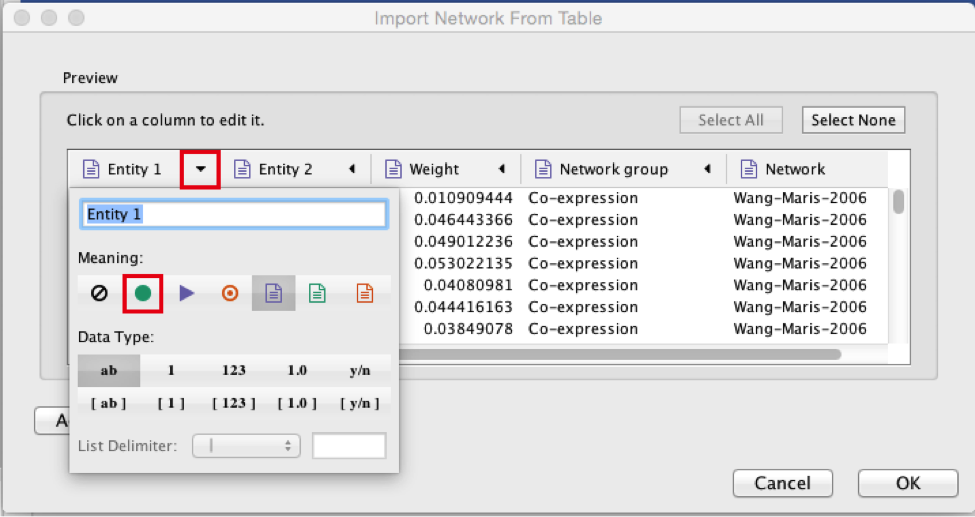
● Select the column ‘Entity 1’ .
● Expand the menu using the arrow on the right and click the green circle button to set this column as ‘Source Node’.
● Select the column ‘Entity 2’.
● Click the red bullseye to set this column as ‘Target Node’.
● Click the ‘OK’ button.
The main window now displays the created network. Each node represents a gene. Edges represent the relationships (e.g physical interactions, co-expression) between the genes (nodes) that were calculated by GeneMANIA in the previous exercise. Tip: The shortcut ⌘+L (Mac) or Ctrl+L (Windows) is a quicker way to import a network from a file.
3) Improve the layout.
● In the menu bar, select Layout > Prefuse Directed Layout, weight.
4) Select all nodes in the network. To do this using the mouse, press shift and drag from an empty space to the left of and above every node to an empty space to the right of and beneath every node. The selected nodes are now colored yellow.
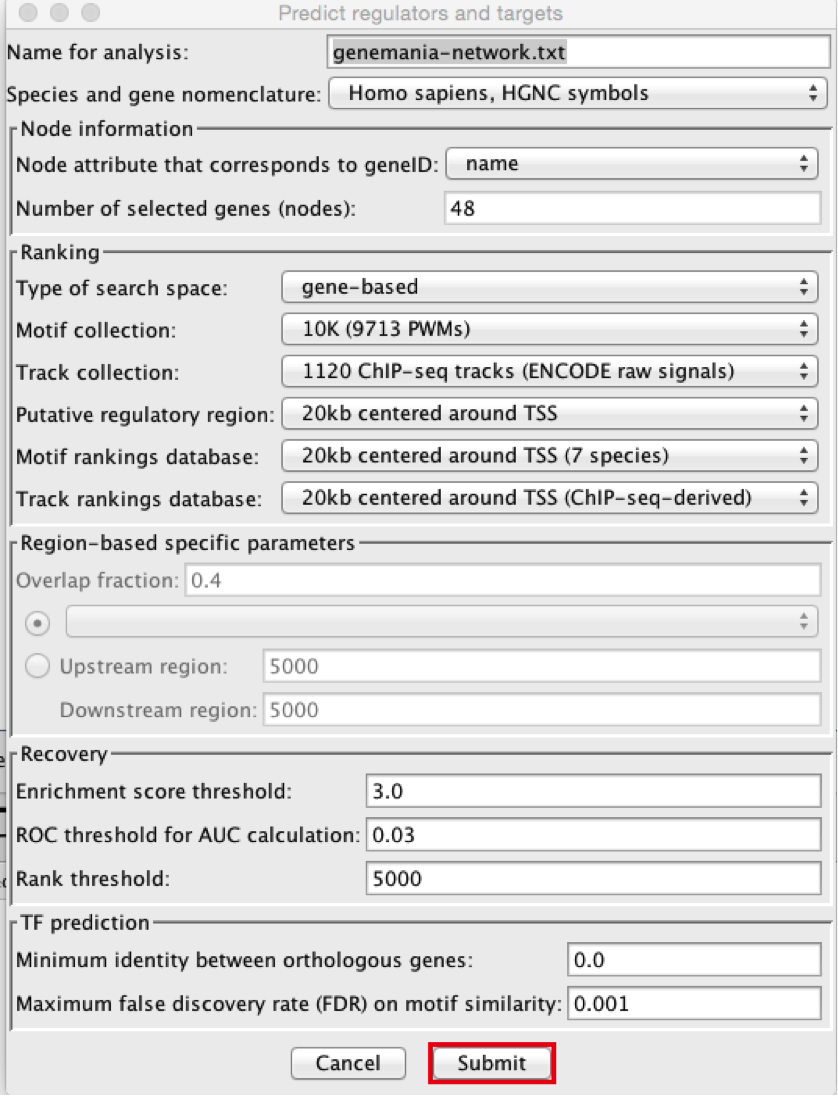
5) In the menu bar, select Apps > iRegulon > Predict regulators and targets. A ‘Predict regulators and targets’ dialog pops up.
● Using the default parameters, click the ‘Submit’ button at the bottom of the page. A progress bar will pop up.
● Wait until the running analysis is completed (usually less than 1 min). The progress bar will vanish, and a new right panel, “Results Panel” will be added to the main Cytoscape window.
● Deselect all nodes by clicking on a blank space of the screen. The nodes are all cyan again.
6) Explore the results.
● Locate the ‘Results Panel’ on the right side of the window.
● Click on the ‘float window’ icon (small square) located at the upper right corner.
● Tip: resize the ‘Result Panel’ window by expanding it horizontally and vertically, so you can see the results and the network simultaneously.
● Tip: mouse over column names to get a tooltip describing their meaning in more detail.
7) Explore the enrichment results in the Motifs tab from the Results Panel. It is a list of all DNA binding motifs that appear in more than one gene region from the prostate cancer gene list. They are ranked by the strongest Normalized Enrichment Score (NES). Some DNA binding motifs in the databases are related to a specific transcription factor, but others are not.
● Check that ‘Motifs’ is the selected tab of the ‘Results Panel’.
● Which is the first motif with an associated TF? (Tip: use the information displayed in the “TFs” column).
● Click on the row for this motif to display the motif’s sequence logo and related information at the bottom part of Results Panel.
● Click on the sequence logo to zoom in on it.
● What are the potential target genes for this TF? (Tip: look at the ‘Target Name’ column at the bottom right of the result panel, red font).
● Tip: some explanation about the results are located at the end of this document and in more detail in the iRegulon reference paper.
8) Explore the enrichment results in the Tracks tab. It is a list of all ChIP-seq datasets (or “tracks”) sorted by strongest enrichment from genes in our network.
● Select the ‘Tracks’ tab of the ‘Results Panel’.
● Find a ‘ClusterCode’ assigned to more than one track (eg the cluster T4 corresponds to 2 tracks). What is the name of the associated TF (‘Transcription Factor Name’)?
● What is the difference between the two tracks?
● Compare and contrast the target genes for the two tracks.
9) Explore the enrichment results in the Transcription Factors tabview. Each row is a TF that is a potential co-regulator of the genes in our network. Each row represents a cluster that combines related motifs or tracks or both.
● Select the ‘Transcription Factors’ tab of the ‘Results Panels’.
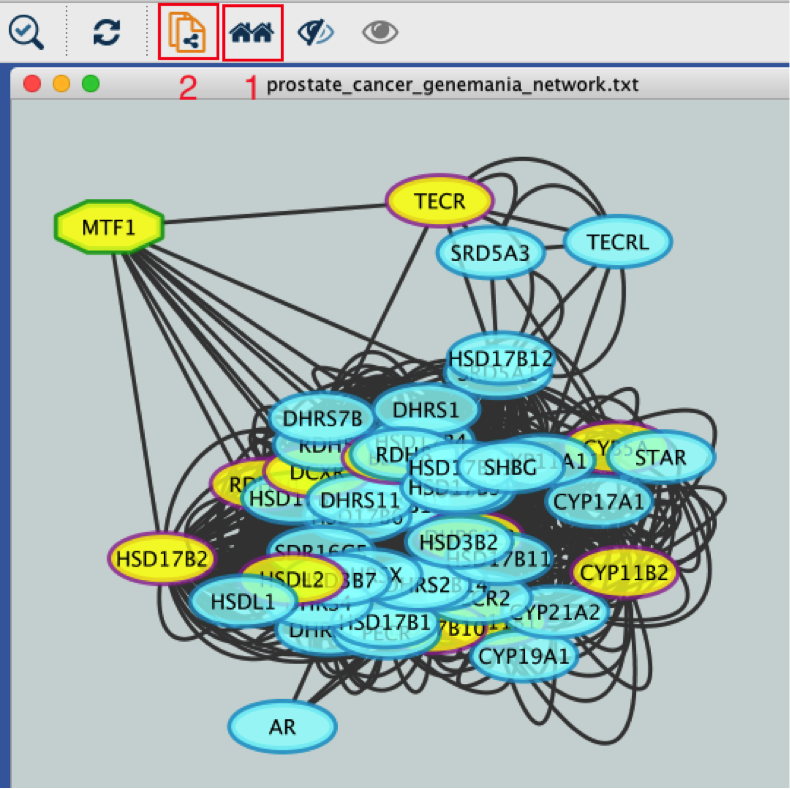
● Click on ‘MTF1’ and explore the results.
10) How did iRegulon perform? Is MTF1 (metal-transcription factor 1) known to be expressed or to play a role in prostate cancer?
● Tip: Open your web browser and search the web for [MTF1 “prostate cancer”].
11) Add MTF1 to the network.
● Check that the Transcription Factors tab is selected.
● Click the MTF1 row to select it.
● Click the ‘Add regulator’ icon  located at the upper left corner of the ‘Results Panel’. This adds MTF1 to the network as a yellow node, with the edges linking to its 11 potential targets, all highlighted as purple nodes.
located at the upper left corner of the ‘Results Panel’. This adds MTF1 to the network as a yellow node, with the edges linking to its 11 potential targets, all highlighted as purple nodes.
12) Create a subnetwork to better visualize the predicted targets.
● Select the MTF1 node in the network by clicking on it.
● In the Cytoscape toolbar above the network, click the ‘First Neighbors of Selected Nodes’ icon  . MTF1 and its targets are now highlighted in yellow (which means they are selected).
. MTF1 and its targets are now highlighted in yellow (which means they are selected).
● Use the ‘New network from selection’ icon  to create a subnetwork.
to create a subnetwork.
13) As the file (‘prostate_cancer_genemania_network.txt’) that we have used to create the network in step 1 is a geneMANIA network, it contains the source of interactions between the nodes: the co-expression, co-localization, physical interaction, predicted interactions and shared protein domains networks. In this step, we will color the edges based on the geneMANIA interaction networks:
● In the Control Panel at the left of the window, select the ‘Style’ tab. At the bottom of the panel, select the ‘Edge’ tab.
● Locate the ‘Stroke Color’ property and click the right triangle to expand the box.
● Change the ‘Column’ field to ‘Network group’
● Verify that the ‘Mapping Type’ field is ‘Discrete Mapping’
● A number of different interaction types such as “co-expression” should appear. For the first of these interaction types, choose a color by clicking on the ‘Edit color’ button on the right side of the color field. Choose a color and click the ‘OK’ button.
● Repeat that step, choosing a different color for each interaction type. The edges should now be colored by the types of interactions.
14) Save current results as an iRegulon (iRF) file.
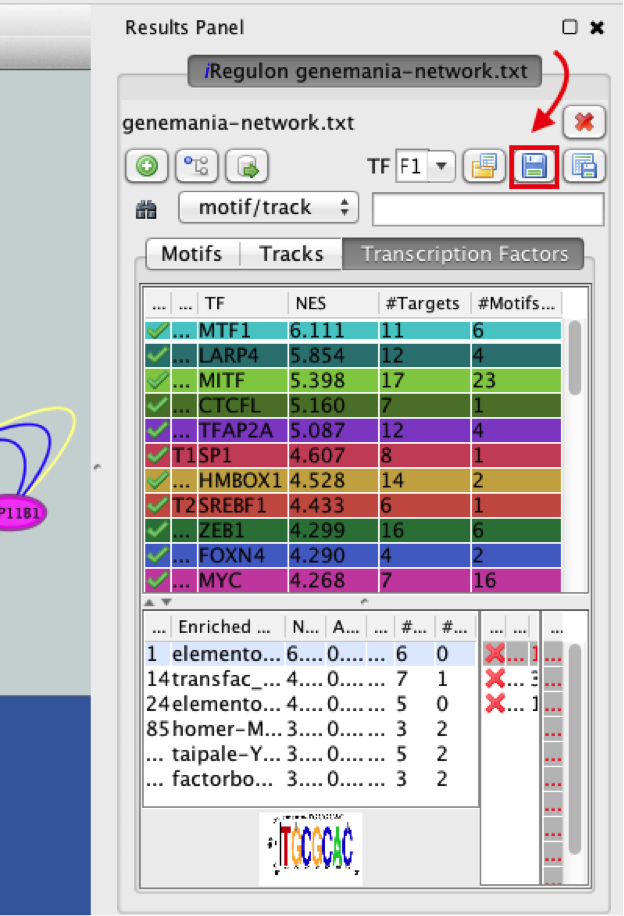
● In the ‘Results Panel’ toolbar, click the ‘Save current results as an iRegulon (iRF) file’ button  .
.
● Choose a name and click the ‘Save’ button.
● Tip: you can reuse these iRegulon results by loading this iRF file using the ‘Load saved results’ icon  ..
..
15) Save the Cytoscape session .
● In the Cytoscape menu bar, select File > Save as.
● Choose a name and click the ‘Save’ button.
● Tip: you can re-open this file later to examine the network further.
ANSWERS EXERCISE 1
1) Launch Cytoscape. Close the “Welcome to Cytoscape” window, if it’s enabled.
Double click on the  . Cytoscape icon.
. Cytoscape icon.
2) Create a network using the ‘prostate_cancer_genemania_network.txt’ file.
● In the menu bar select ‘File > Import > Network >File…. A file open dialog pops up.
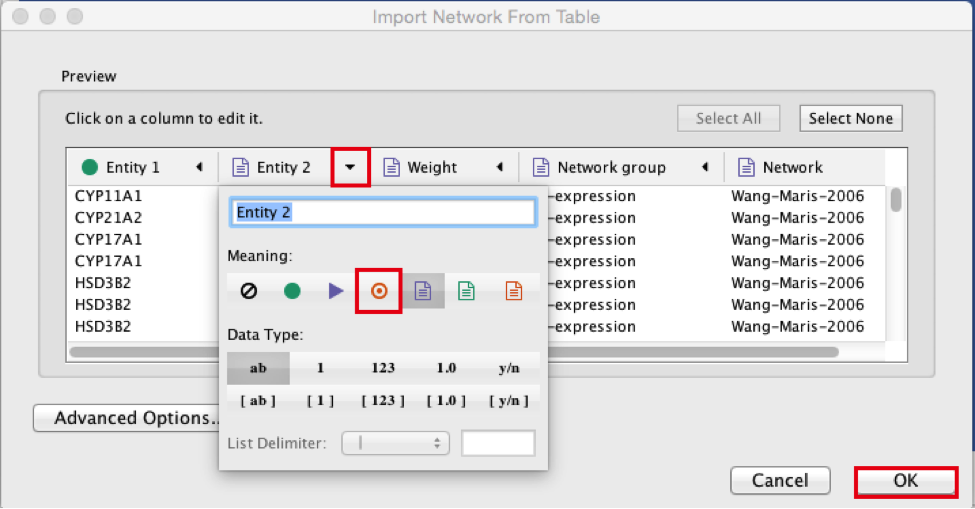
● Browse and locate the prostate_cancer_genemania_network.txt’ file. Click the ‘Open’ button. An “Import Network From Table” dialog pops up.
● Select the column ‘Entity 1’ .
● Expand the menu using the arrow on the right and click the green circle button to set this column as ‘Source Node’.
● Select the column ‘Entity 2’.
● Click the red bullseye to set this column as ‘Target Node’.
● Click the ‘OK’ button. The main window now displays the created network. Each node represents a gene. Edges represent the relationships (e.g physical interactions, co-expression) between the genes (nodes) that were calculated by GeneMANIA in the previous exercise. Tip: The shortcut ⌘+L (Mac) or Ctrl+L (Windows) is a quicker way to import a network from a file.
2a)
2b)
2c)
2d)
2e)

3) Improve the layout.
● In the menu bar, select Layout > Files Layouts > Organic.
3a)
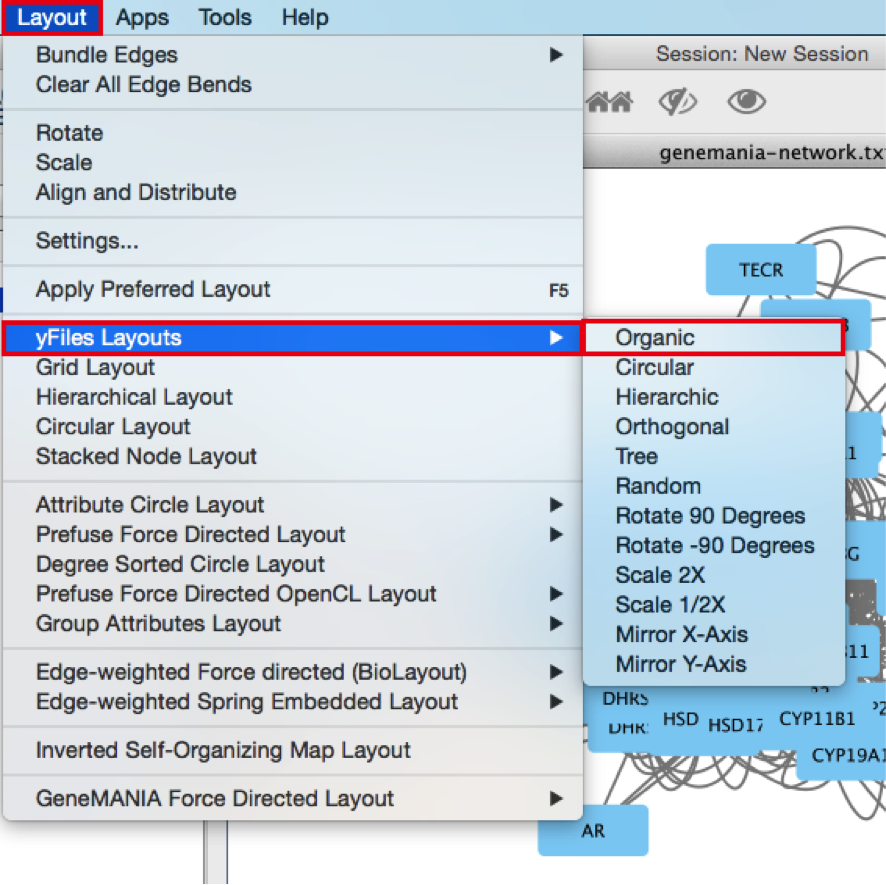
3b)

4) Select all nodes in the network. To do this using the mouse, drag from an empty space to the left of and above every node to an empty space to the right of and beneath every node. The selected nodes are now colored yellow.
5) In the menu bar, select Apps > iRegulon > Predict regulators and targets.A ‘Predict regulators and targets’ dialog pops up.
● Using the default parameters, click the ‘Submit’ button at the bottom of the page.A progress bar will pop up.
● Wait until the running analysis is completed (usually less than 1 min). The progress bar will vanish, and a new right panel, “Results Panel” will be added to the main Cytoscape window.
● Deselect all nodes by clicking on a blank space of the screen. The nodes are all cyan again.
5a)
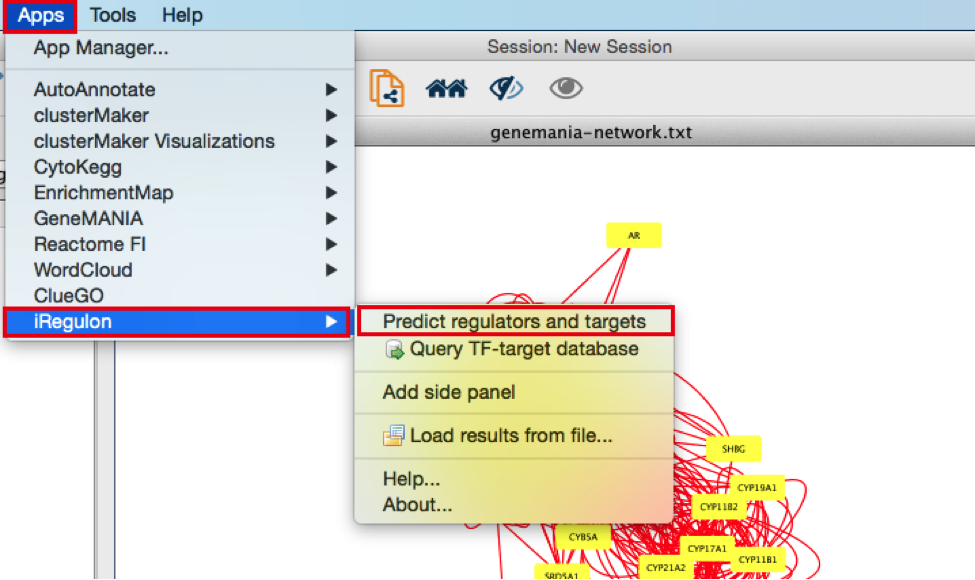
5b)
6) Explore the results.
● Locate the ‘Results Panel’ on the right side of the window.
● Click on the ‘float window’ icon located at the upper right corner.
● Tip: resize the ‘Result Panel’ window by expanding it horizontally and vertically, so you can see the results and the network simultaneously. Tip: mouse over column names to get a tooltip describing their meaning in more detail.
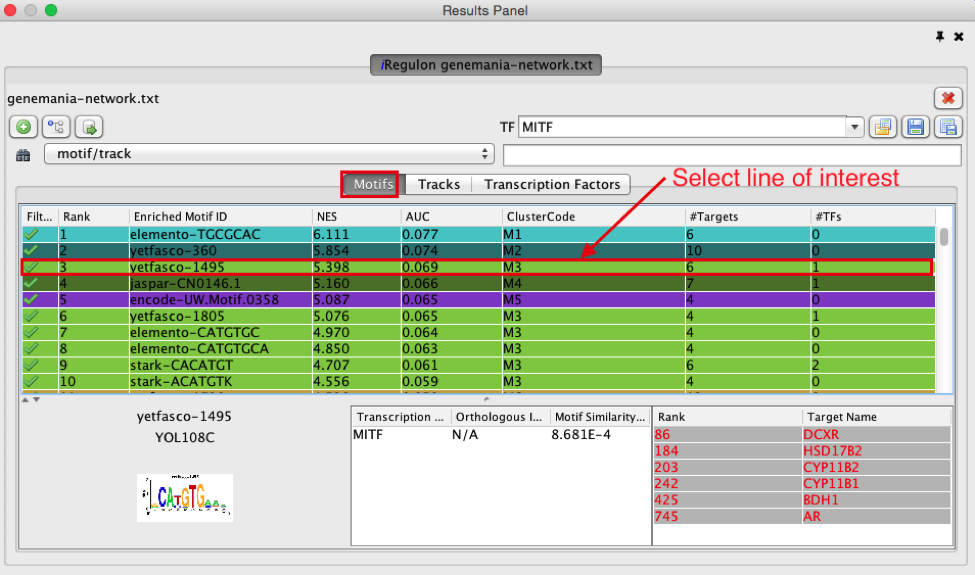
7) Explore the enrichment results in the Motifs tab from the Results Panel. It is a list of all DNA binding motifs that appear in more than one gene region from the prostate cancer gene list. They are ranked by the strongest Normalized Enrichment Score (NES). Some DNA binding motifs in the databases are related to a specific transcription factor, but others are not.
● Check that ‘Motifs’ is the selected tab of the ‘Results Panel’.
● Which is the first motif with an associated TF? (Tip: use the information displayed in the “TFs” column).
● Click on the row for this motif to display the motif’s sequence logo and related information at the bottom part of Results Panel.
● Click on the sequence logo to zoom in on it.
● What are the potential target genes for this TF? (Tip: look at the ‘Target Name’ column).
Tip: some explanation about the results are located at the end of this document and in more detail in the iRegulon reference paper.
8) Explore the enrichment results in the Tracks tab. It is a list of all ChIP-seq datasets (or “tracks”) sorted by strongest enrichment from genes inour network.
● Select the ‘Tracks’ tab of the ‘Results Panel’.
● Find a ‘ClusterCode’ assigned to more than one track. What is the name of the associated TF?
● What is the difference between the two tracks?
● Compare and contrast the target genes for the two tracks.
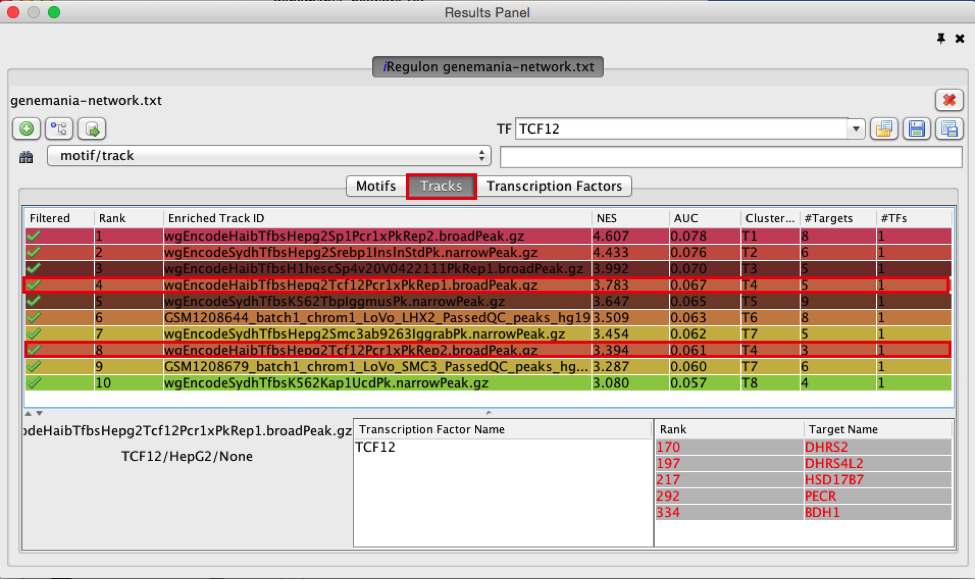
Answer:
T4 is a track cluster associated with 2 tracks. The first track is ranked number 4 and the second track is ranked number 8. The transcription factor is TCF12. The 2 tracks are probably biological replicates (Rep1, Rep2) of a same Chip-seq experiment. They have only 1 target in common (DHRS2) but 4 targets (DHRS) are from the same protein family (shared protein domains). On the Transcription Factors view (see section below), all these target genes are combined under cluster T4 corresponding to TCF12. T7 is also associated with 2 tracks and correspond to SMC3.
9) Explore the enrichment results in the Transcription Factors tabview. Each row is a TF that is a potential co-regulator of the genes in our network. Each row represents a cluster that combines related motifs or tracks or both.
● Select the ‘Transcription Factors’ tab of the ‘Results Panels’.
● Click on ‘MTF1’ and explore the results.
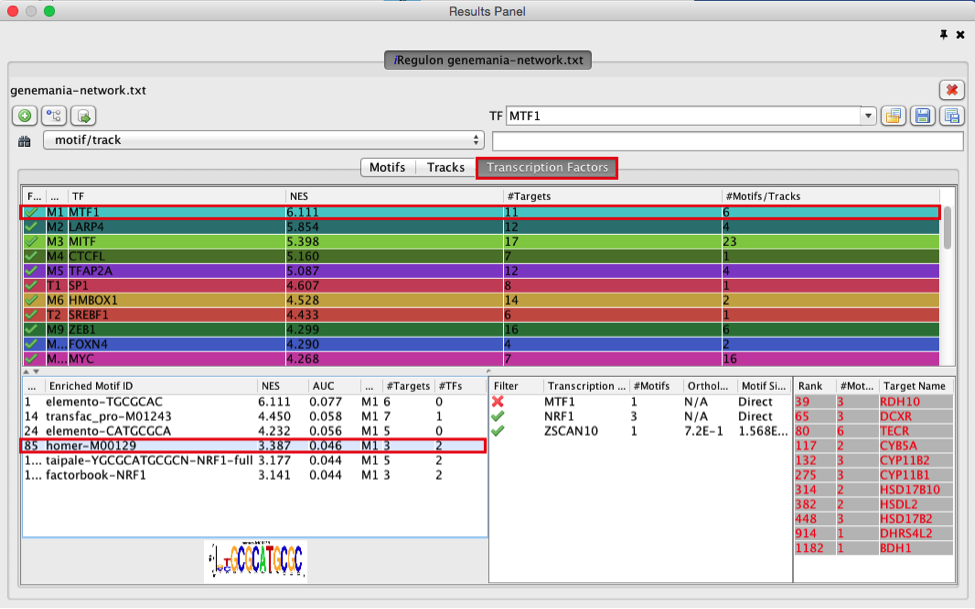
Answer: MTF1 is associated with the motif cluster M1. This cluster contains 6 related motifs and 11 potential target genes. One motif (homer-M00129) selected as example in the above screenshot is directly annotated to the TFs NRF1 and ZSCAN10 as indicated by green checked signs.
10) How did iRegulon perform? Is MTF1 (metal-transcription factor 1) known to be expressed or to play a role in prostate cancer?
Tip: Open your web browser and search the web for [MTF1 “prostate cancer”].
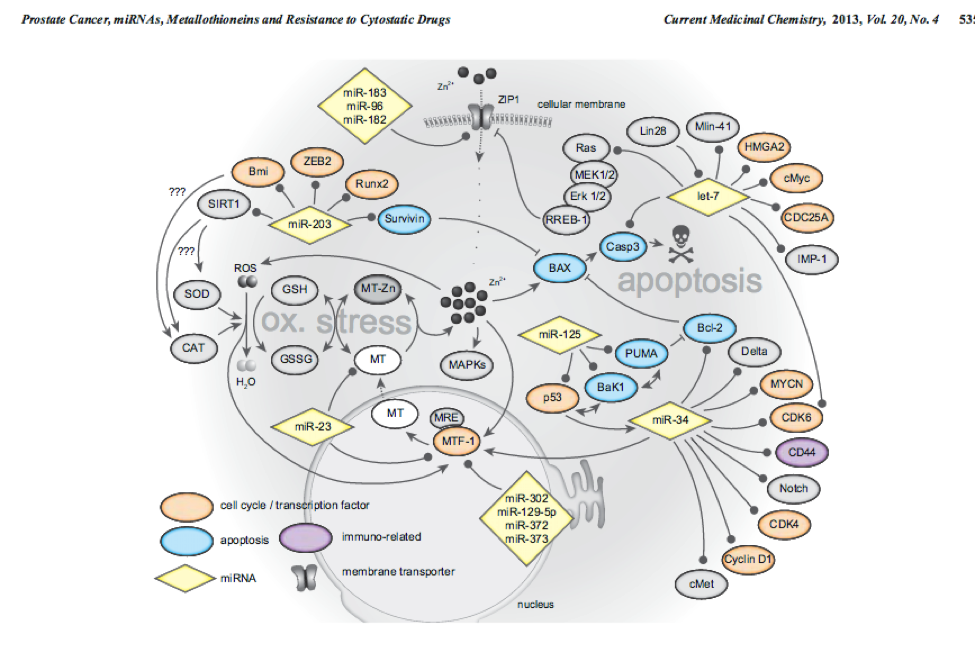
This network MTF1 within genes and miRs important for prostate cancer. PMID:14568174 PMID:23157640
11) Add MTF1 to the network.
● Check that the Transcription Factors tab is selected.
● Click the MTF1 row to select it.
● Click the ‘Add regulator’ icon located at the upper left corner of the ‘Results Panel’.
This adds MTF1 to the network as a yellow node, with the edges linking to its 11 potential targets, all highlighted as purple nodes.
11a)
11b)
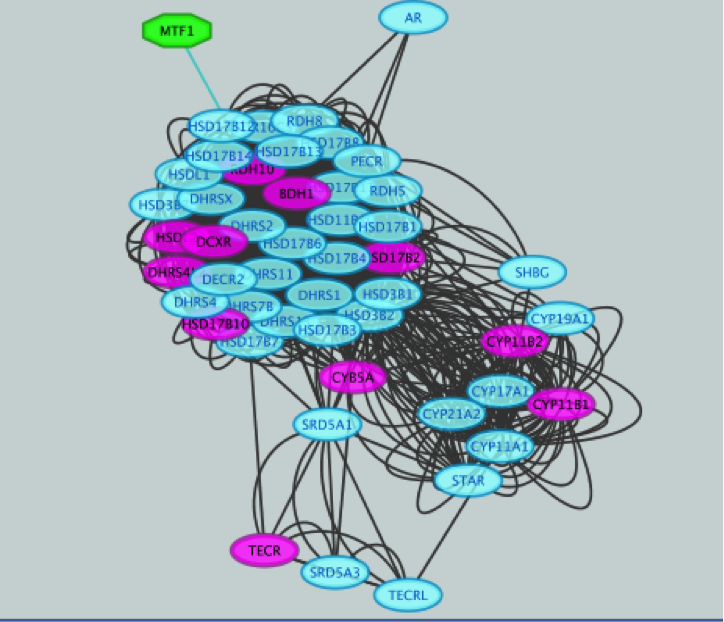
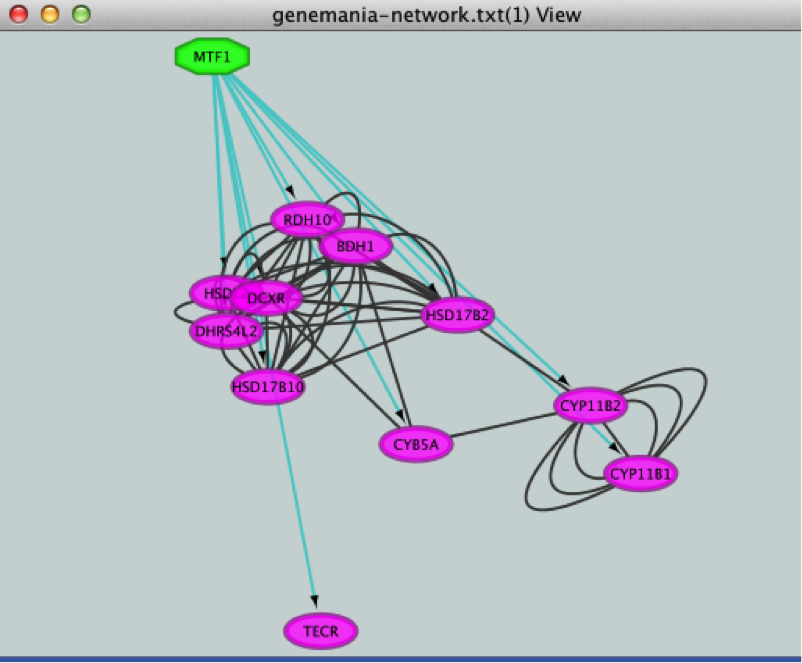
12) Create a subnetwork to better visualize the predicted targets.
● Select the MTF1 node in the network by clicking on it.
● In the Cytoscape toolbar above the network, click the ‘First Neighbors of Selected Nodes’ icon . MTF1 and its targets are now highlighted in yellow (which means they are selected).
● Use the ‘New network from selection’ icon to create a subnetwork.
12a)
12b)
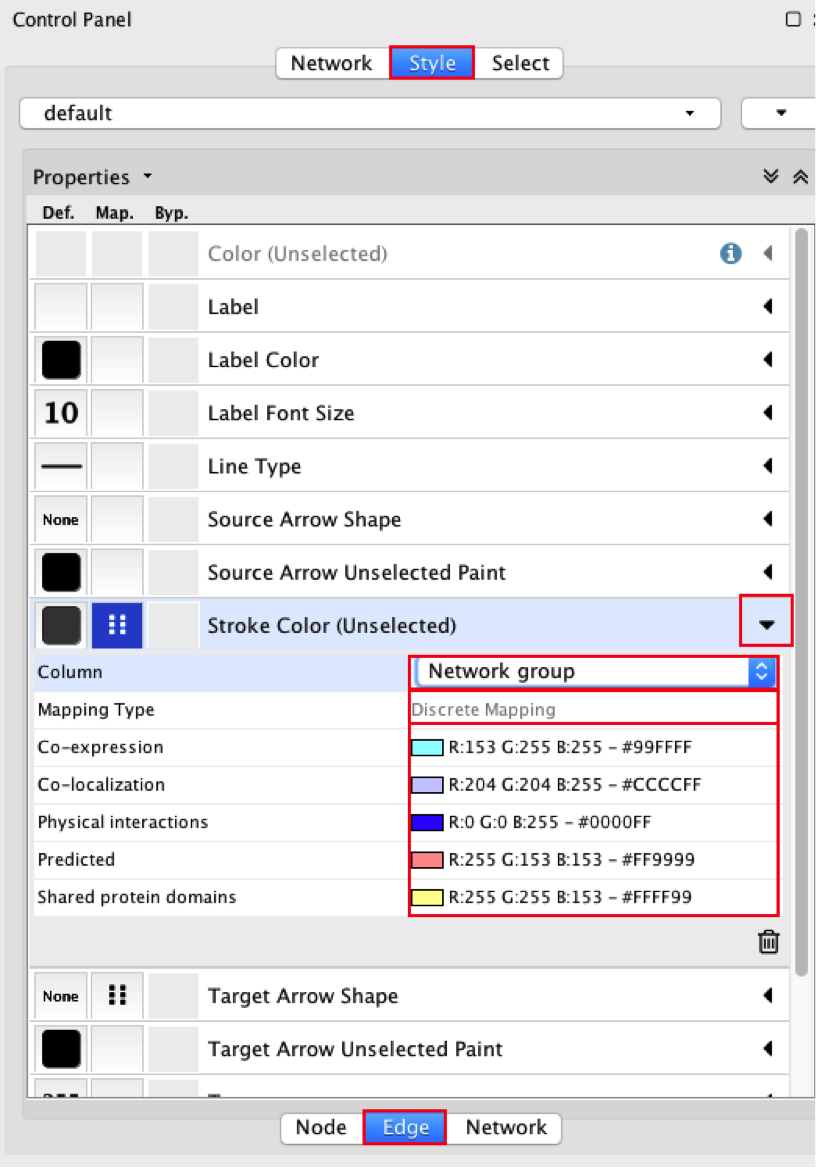
13) Add to the figure information on the types of interactions obtained from GeneMANIA and stored as additional information in the ‘prostate_cancer_genemania_network.txt’ file.
● In the Control Panel at the left of the window, select the ‘Style’ tab. At the bottom of the panel, select the ‘Edge’ tab.
● Locate the ‘Stroke Color’ property and click the right triangle to expand the box.
● Change the ‘Column’ field to ‘Network group’
● Verify that the ‘Mapping Type’ field is ‘Discrete Mapping’
● For the first interaction type, choose a color by clicking on the ‘Edit color’ button on the right side of the color field. Choose a color and click the ‘OK’ button.
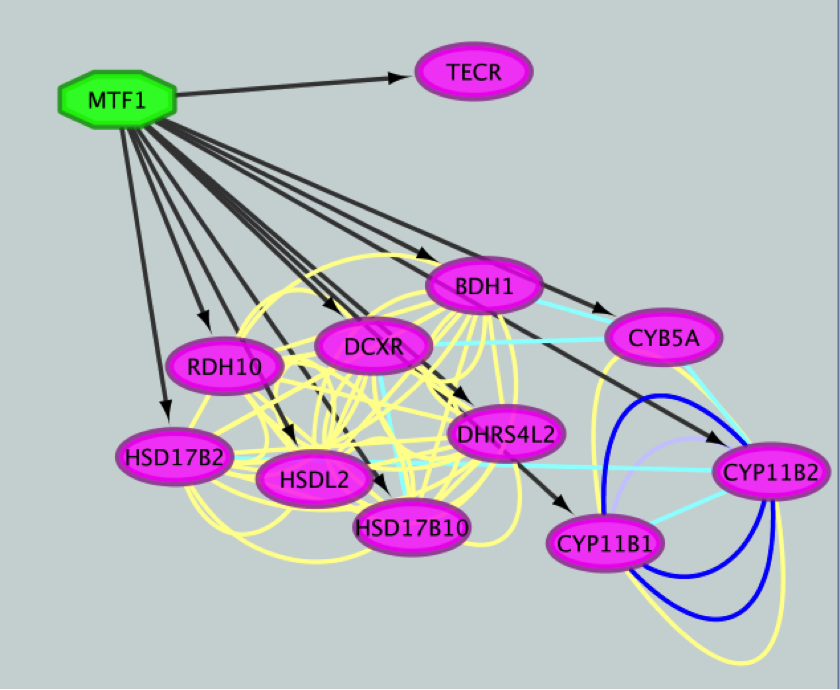
● Repeat that step, choosing a different color for each interaction type. The edges should now be colored by the types of interactions.
13a)
13b)
14) Save current results as an iRegulon (iRF) file.
● In the ‘Results Panel’ toolbar, click the ‘Save current results as an iRegulon (iRF) file’ button  ..
..
● Choose a name and click the ‘Save’ button.
Tip: you can reuse these iRegulon results by loading this iRF file using the ‘Load saved results’ icon ..
14a)
15) Save the Cytoscape session .
● In the Cytoscape menu bar, select File > Save as.
● Choose a name and click the ‘Save’ button. Tip: you can re-open this file later to examine the network further.
Exercise 2. Create a metatargetome using iRegulon and merge 2 networks in Cytoscape.
This exercise does not require additional files.
This exercise will teach you to use the metatargetome function of iRegulon. This function displays a list of potential targets for a specific TF. We will create the metatargetome of two TFs, that we found as potential coregulators of the prostate cancer genes (exercise 1): MTF1 and LARP4. We will then learn how to use Cytoscape to merge two networks and visualize nodes in common.
Steps
1) Launch Cytoscape. If Cytoscape is already opened, do File > New > Session. A ‘Current session will be lost. Do you want to continue?’ dialog opens. Click on ‘OK’.
2) Create the metatargetome for MTF1.
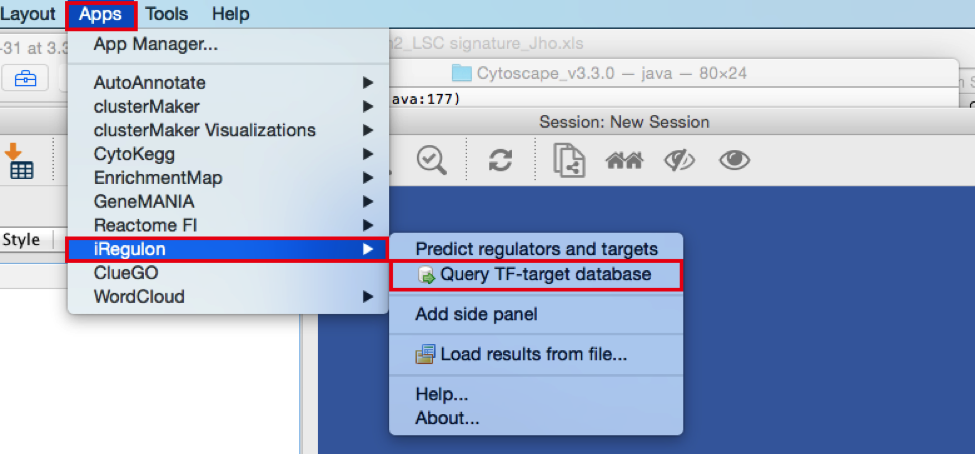
● From the menu bar , select Apps > iRegulon > Query TF-target database.A ‘Query TF-target database for a factor’ window pops up.
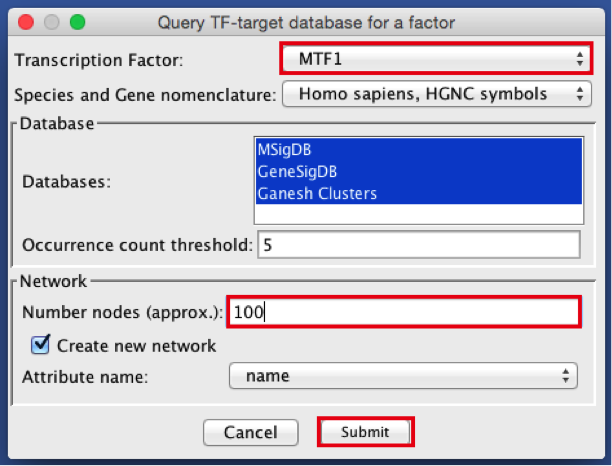
● In the ‘Transcription Factor’ field, select ‘MTF1’.
● Set Network > ‘Number nodes (approx.)’ to 100.
● Click the ‘Submit’ button.
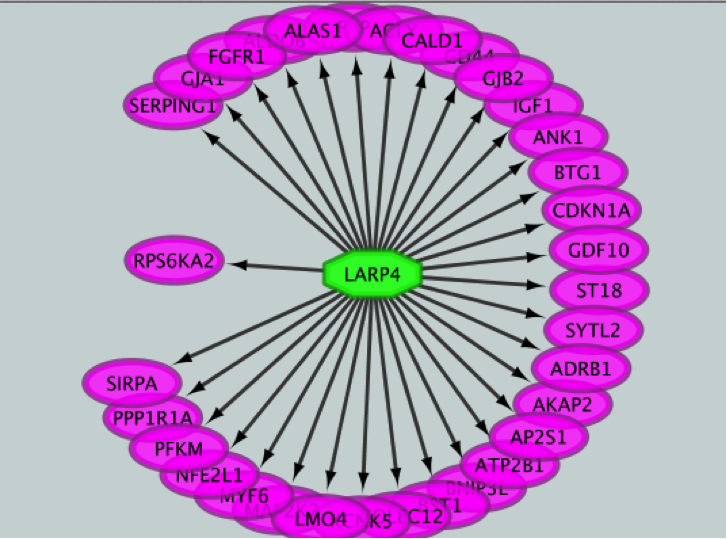
3) Create the metatargetome for LARP4. Follow same steps as above.
● From the Cytoscape menu bar, select Apps > iRegulon > Query TF-target database.
● A ‘Query TF-target database for a factor’ window pops up. In the ‘Transcription Factor field’, enter ‘LARP4’.
● Set Network > ‘Number nodes (approx.)’ to 100.
● Click the ‘Submit’ button.
4) Merge the two networks to visualize their shared target genes. From the Cytoscape menu bar, select Tools > Merge > Networks….An ‘Advanced Network Merge’ window pops up.
● Check that the ‘Union’ option is selected.
● In the ‘Available Networks’ list, select ‘Metatargetome for LARP4’.
● Hold down the shift key while selecting ‘Metatargetome for MTF1’ so both networks are selected.
● Click the right arrow to move the networks to the ‘Networks to Merge’ list.
● Click the ‘Merge’ button. Cytoscape now displays the two networks in the same window, linked by the two genes they have in common.
ANSWERS EXERCISE 2
1) Launch Cytoscape.
If Cytoscape is already opened, do File > New > Session. A ‘Current session will be lost. Do you want to continue?’ dialog opens. Click on ‘OK’.
Double click on the Cytoscape icon.
2) Create the metatargetome for MTF1.
● From the menu bar , select File > Apps > iRegulon> Query TF-target database.A ‘Query TF-target database for a factor’ window pops up.
● In the ‘Transcription Factor’ field, select ‘MTF1’.
● Set Network > ‘Number nodes (approx.)’ to 100.
● Click the ‘Submit’ button.
2a)
2b)
2c)

3) Create the metatargetome for LARP4. Follow same steps as above.
● From the Cytoscape menu bar, select File > Apps>iRegulon> Query TF-target database.
● A ‘Query TF-target database for a factor’ window pops up. In the ‘Transcription Factor field’, enter ‘LARP4’.
● Set Network > ‘Number nodes (approx.)’ to 100.
● Click the ‘Submit’ button.
3a)
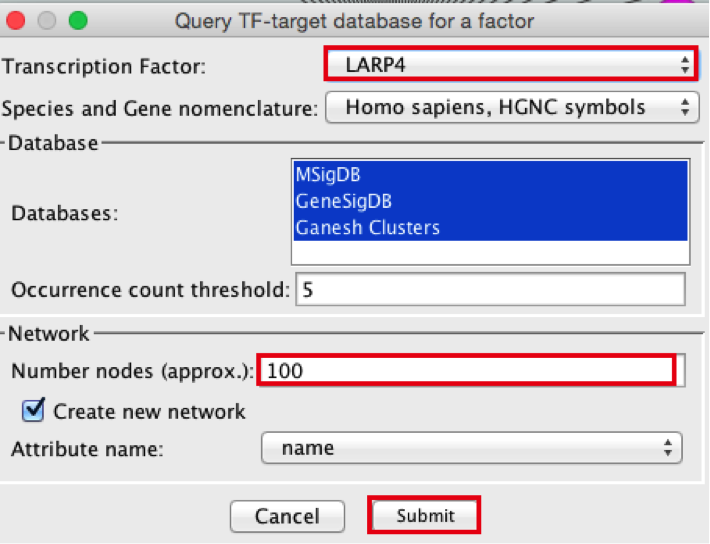
3b)
4) Merge the two networks to visualize their shared target genes. From the Cytoscape menu bar, select Tools > Merge > Networks….An ‘Advanced Network Merge’ window pops up.
● Check that the ‘Union’ option is selected.
● In the ‘Available Networks’ list, select ‘Metatargetome for LARP4’.
● Hold down the shift key while selecting ‘Metatargetome for MTF1’ so both networks are selected.
● Click the right arrow to move the networks to the ‘Networks to Merge’ list.
● Click the ‘Merge’ button. Cytoscape now displays the two networks in the same window, linked by the two genes they have in common.
4a)
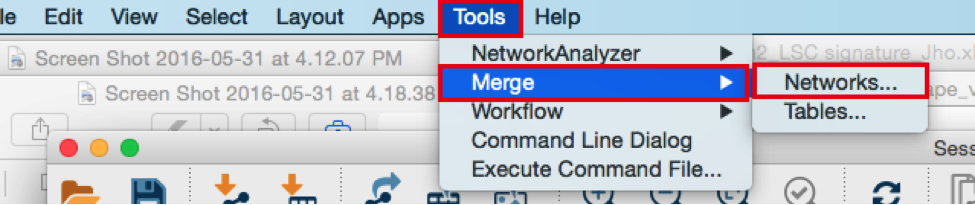
4b)
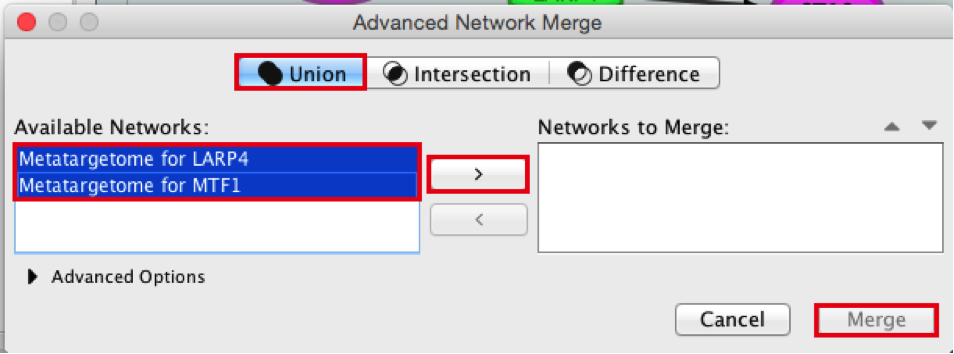
4c)
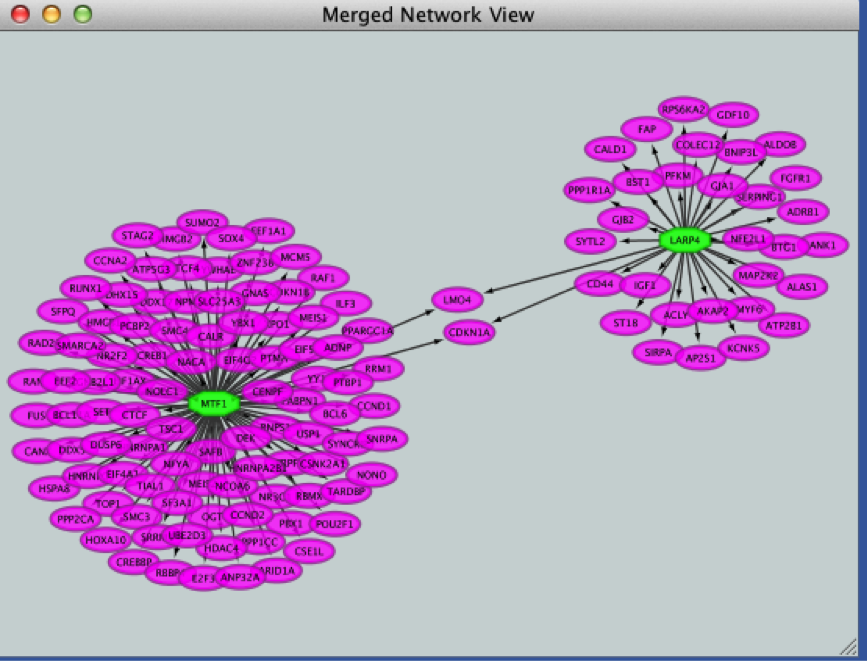
END OF EXERCISE
Use or precomputed iRegulon results:
Download these files on your computer:
1) launch Cytoscape
2) open the “prostate_cancer_genemania_network.cys” file
3) go to App > iRegulon > ‘Load results from the iregulon_results.irf file’
Notes about iRegulon:
Website: http://iregulon.aertslab.org/ Tutorials: http://iregulon.aertslab.org/tutorial.html#clusters Paper: http://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1003731 [PMID:25058159]
Motif oriented view:
Each line is a DNA binding motif those sequence has been located in 20 kb regions centered around the TSS (transcription start site) of genes from the prostate cancer list (= genes in the network). The genes from the network which contained this DNA binding motif are called the target genes and displayed in the ‘Target Name’ column. Their ranks are also indicated.
DNA binding motifs more usually represent a family of transcription factors (e.g. helix loop helix TFs ) rather than being specific to one particular TF. In addition, related TFs (e.g GATA1, GATA2, GATA3) can bind to very similar DNA sequences. iRegulon uses the motif2TF algorithm to associate a motif with a specific TF. The ‘#TF’ column indicates which motifs are significantly associated to a TF (# >= 1) or not (# = 0). Clicking on a motif line will display a panel indicating several related information. It will display all the TFs found significantly associated with the motif.
How is the enrichment calculated? (NES AUC) motif detection and enrichment score in a set of input genes. iRegulon uses precomputed results to calculate for each motif the AUC (Area Under the cumulative Recovery Curve) and the NES (Normalized Enrichment Score). iRegulon accesses this database of precomputed results using a server connection when a search is launched.
What are these precomputed results :
iRegulon gathered known DNA binding motifs and their corresponding PWM (position weight matrix, see lecture) from different databases (eg TRANSFAC pro) (9713 PWMs). They then ranked all genes in the genome (22284 genes) for each motif from the most likely target of this motif to the least one (available for Human, Mouse and Drosophila).
Calculating enrichment for our set of genes (our network) :
Each ranked list (each motif) is then tested with our set of genes to see whether genes in our list are located more at the top of the ranked list (most likely targets of the motifs). From this ranked list and the overlap with our gene list, the AUC (Area Under the cumulative Recovery Curve) is calculated for each motif. The AUC is going to be larger if we have more genes at the top of our list. The higher the AUC values and the higher the tested motif is likely to co-regulate our genes (or some of them). The NES is derived from the AUC. The optimal subset of highly ranked lists are set as the potential target genes and displayed in the ‘target name’ column.
How are several motifs being similarly grouped under a same cluster code?
To find TF associated with motifs, iRegulon uses the motif2TF algorithm. During this computation of motif2TF, motifs sharing similarities are grouped together and form a cluster. Within this cluster, some motifs are already known to correspond to a specific TF (direct annotation). This information is used to associate a motif with one or more related TFs. The ‘ClusterCode’ column indicates the cluster assigned to each motif.
Tracks oriented view:
Each line is an ENCODE Chip_Seq track. Chip_seq are sequencing of fragments bound to a specific TF after immunoprecipitation of the TF and the DNA fragments. Each track is then specific to a transcription factor (the #TFs columns is always equal to 1). Clusters contain more than one track only if these tracks were generated using the same TF. All the values (NES, AUC,… are the same for the motif, track of transcription factor oriented views.
Transcription Factors oriented view:
Each line is a cluster of motifs and or tracks and as the next column (TF) the best representative TF of this cluster determined by the motif2TF algorithm. All the values (NES, AUC,… are the same for the motif, track of transcription factor oriented views.
Metatargetome:
iRegulon uses the pre-computed results not only for finding regulons but also for displaying the potential gene targets for any TF of interest available in the iRegulon database. Users can define the number of top potential targets they want to display. The result is visualized as a network using a circular layout with the TF of interest in the center of the network.
Notes about Cytoscape:
Link to tutorials showing how to format data to create a Cytoscape network starting from a simple gene list: http://wiki.cytoscape.org/Cytoscape_User_Manual/Network_Formats
Note about organic layout:
“The organic layout style is based on the force-directed layout paradigm. When calculating a layout, the nodes are considered to be physical objects with mutually repulsive forces, like, e.g., protons or electrons. The connections between nodes also follow the physical analogy and are considered to be springs attached to the pair of nodes. … The layout algorithm simulates these physical forces and rearranges the positions of the nodes in such a way that the sum of the forces emitted by the nodes and the edges reaches a (local) minimum.
Resulting layouts often expose the inherent symmetric and clustered structure of a graph, they show a well-balanced distribution of nodes and have few edge crossings.” http://docs.yworks.com/yfiles/doc/developers-guide/smart_organic_layouter.html .